Google Search Console’s New and Improved Crawl Stats Report: Everything you Need to Know

The Crawl Stats Report is the latest feature to be updated in Google Search Console and it is outstanding. Google made this announcement last November 24 in the Google Search Central blog and SEOs are quite excited about it.
If you’re like me who was able to use the old Google Search Console, you would know that the old Crawl Stats report is not that helpful. This new update gives us more relevant and deeper data on how Google crawls our websites and gives us more room for optimizations.
The update is already live as soon as they announced it. Do take note that the new Crawl Stats Report is only available for verified domain-level properties. If you have subdomains, you’ll be able to see reports for them under the main domain if you’re verified using Domain Verification. If you’re using URL Prefix to verify a subdomain, the report will not be available.
In this article, I’ll cover everything that you need to know about the new Crawl Stats Report.
How to access Crawl Stats Report
In your verified Google Search Console property, go to Setting and you should be able to see Crawl Stats. Then, simply click Open Report.
Crawl history
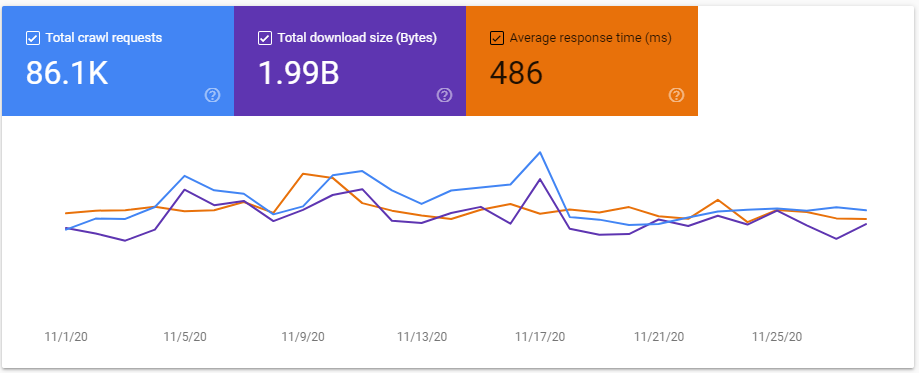
In the Crawl Stats report, you can now see the number of Total Crawl Requests that Google made per day in the last 30 days. The Total Crawl Requests includes both successful and failed crawled requests and includes all resources. If Google crawled the same URL twice during this span, they are both counted as individual requests.
You’ll also be able to see the Total Download Size which is the total bytes Google downloaded from your website during crawling and Average Response Times for all resources.
Crawl breakdown
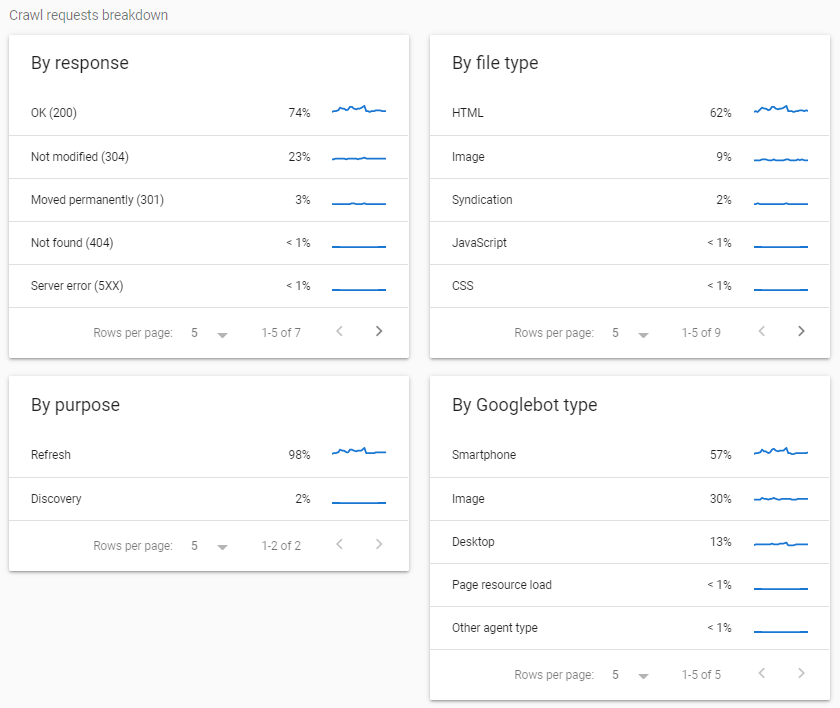
The Crawl Breakdown report is divided into 4: Response, File Type, Purpose, and Googlebot type. Clicking them will show sample URLs.
The Response table groups URLs per their response when Google crawled them. The majority of it should be 200 (Ok) which means Google was able to successfully crawl them. Some notable response codes are 301 (permanent redirect), 301 (temporary redirect), 404 (not found), and 5xx (server error). If you want to see the full list of response codes that Google identifies in this report, click here.
File type lists the type of file that was returned after the request. The majority of this should be HTML. Other possible values according to Search Console Help include:
- Image
- Video – One of the supported video formats.
- JavaScript
- CSS
- Other XML – An XML file not including RSS, KML, or any other formats built on top of XML.
- JSON
- Syndication – An RSS or Atom feed
- Audio
- Geographic data – KML or other geographic data.
- Other file type – Another file type not specified here.
- Unknown (Failed) – If the request fails, the file type isn’t known.
For Crawl Purpose, there are only two types: Discover and Refresh. Discover includes URLs that were crawled by Google for the first time while Refresh means Google recrawled the page.
Lastly, for Googlebot type, it is the user-agent Google used to make the crawl request. Google uses different user-agents depending on the situation. Some of the well-known user-agents would be Googlebot(Desktop) and Googlebot(Smartphone). It is no surprise that the majority of it would be Googlebot(Smartphone) since Google has switched to Mobile-First Indexing in 2019.
Host status
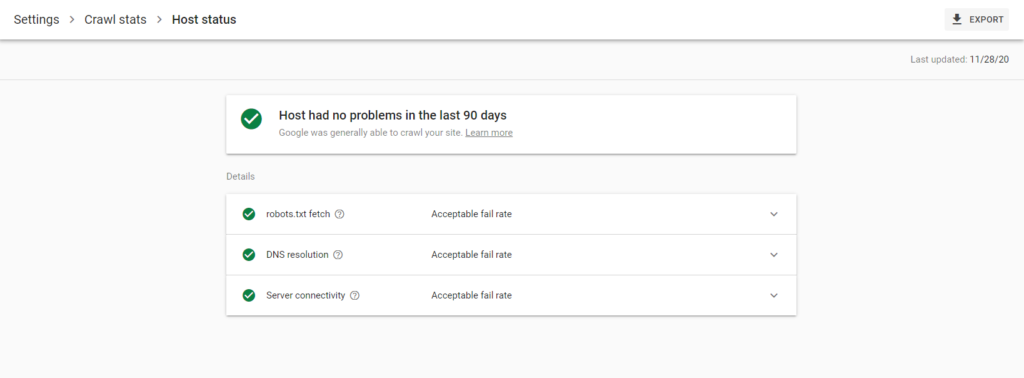
The Host Status sections highlight any problems Google had in trying to crawl your website for the past 90 days. It also shows if robots.txt fetching errors, DNS errors, and server communication errors. This is a critical report because more errors Google encounter here means Google is finding a hard type crawling your website.
What does this mean for SEO?
This new update is a big help for Technical SEO which deals with crawling and indexing of a website. Indexing is the part where Google processes a webpage to appear in the search results. But prior to that, a webpage should be crawled first.
To simply put, if Google is unable to properly crawl your website, they will not be able to index pages or detect any changes made to a certain page and consider it for ranking.
These new insights that are now available to us SEOs make it easier to diagnose problems such as a problem in our hosting, which resources are eating up the crawl budget, error 404s, and more. It is like seeing our website from Google’s point of view.
Managing your Crawl Budget will now be easier as well especially if you own a website with thousands of pages. The number of pages/resources Google crawls on a website everyday may vary. This depends on a lot of different factors but primarily, it is affected by your server’s capacity because Google avoids overloading a website’s server when crawling. Now that you are able to see how much Google is crawling on your website on a daily basis, you can compare it to the actual number of pages in your Coverage Report. If the number of crawled pages/resources is a lot lower, then you may consider using a robots.txt file to manage it and make sure that Google is only crawling important pages.
Key takeaway
I personally am very pleased with this update. Any data that Google share is huge because it gives us more room to operate. Now that we have more data on how Google crawls our websites, we are able to perform fixes and optimizations at a faster rate and overall allow us to manage our crawl budgets better. Remember that crawling is a critical process and making sure Google is able to crawl your website successfully should always be a priority.