Crawled – Currently Not Indexed Google Search Console Status Guide

How do I fix crawled and not currently indexed?
Quick Answer: This problem means that Google has crawled your page, but consciously decided not to include it in the index. There are many reasons why Google would do this, but the main one is that it feels readers wouldn’t benefit from your page. The best solution here might be to improve the quality and length of your content, increase your internal links, and reduce click-depth. Afterward, submit the URL again in Google Search Console for indexing and see if that works.
Overview
For a webpage to appear on Google search, it must undergo two processes; crawling and indexing. Usually, the process is fast and simple, Google discovers the page through crawling and then processes it for indexing. However, there are also times where Google was able to crawl a webpage but it didn’t index it, therefore, not being able to appear in the search results.
These pages fall under the Excluded status type “Crawled – Currently Not Indexed” in Google Search Console. Pages that were crawled but not indexed by Google are common to any website.
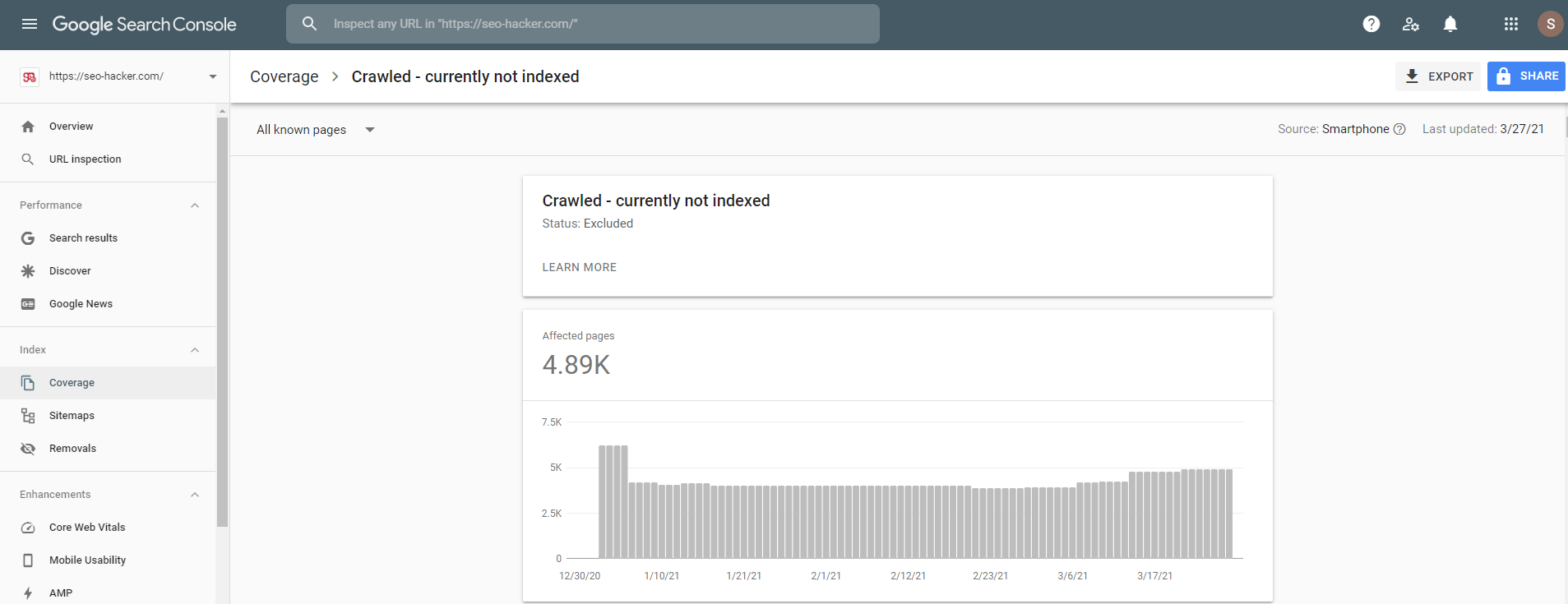
These numbers can be alarming to some. Usually, the higher the number of pages a website has, the more pages are added to this status. However, these numbers don’t tell the whole story and there’s not much to see really aside from the number of pages and the URLs included in the list.
In this blog post, I’ll cover what you need to know about the ‘Crawled – Currently Not Indexed’ status in Google Search Console.
What is ‘Crawled – Currently Not Indexed” in Google Search Console?
Crawled – Currently Not Indexed is a status type under Excluded in Google Search Console. URLs listed under this status type were already crawled by Google but it decided to not index it momentarily. According to Google Search Console Help Center, Google may decide to index or not index it in the future.
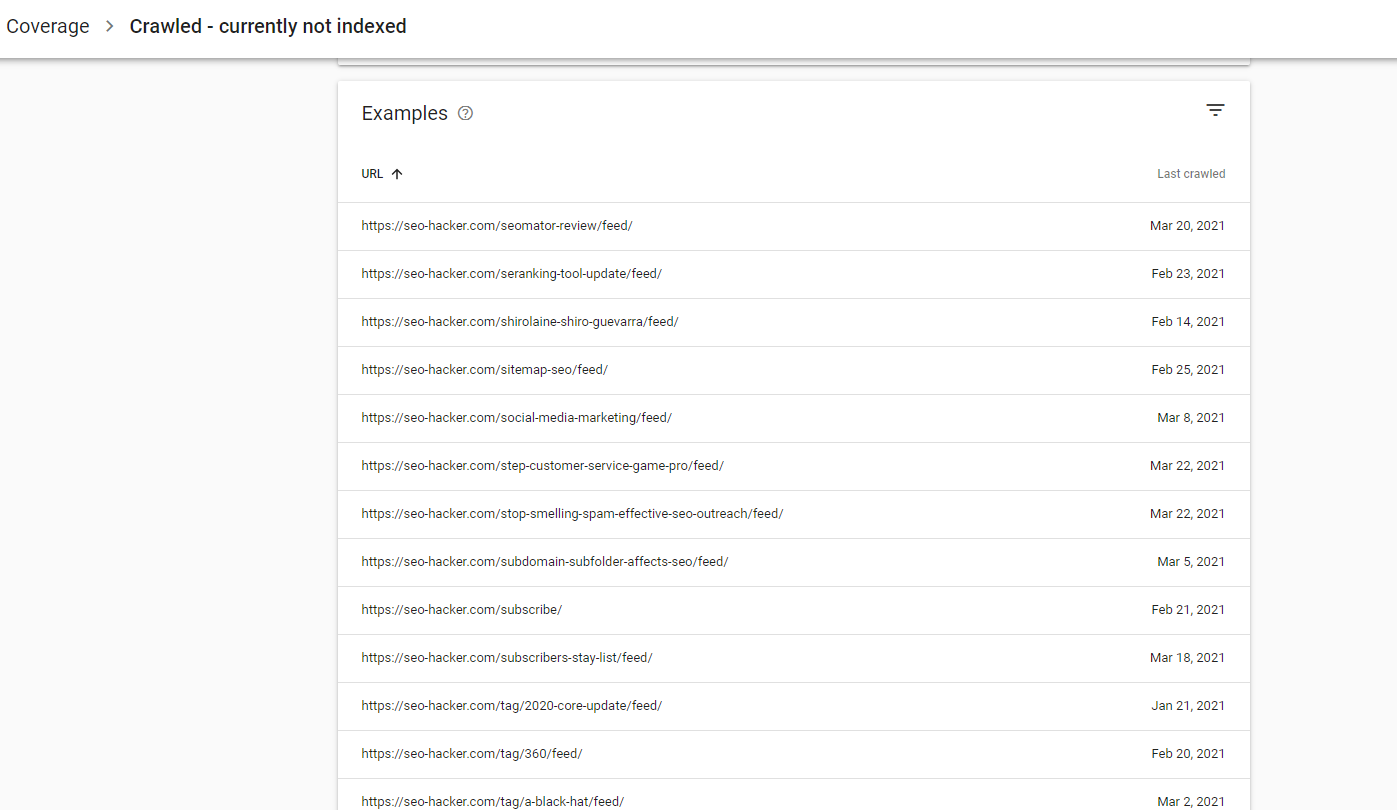
If you check your Google Search Console account and you’re seeing pages such as tags, categories, archives, and feed, there is no need for you to worry. However, if you’re seeing important pages here such as landing pages, product pages, and blog posts, then you may need to start to evaluate these pages individually.
Why is Google Not Indexing These Pages?
Google is Still Processing Fresh Data
When Google first crawls a website or a single page, it takes time for Google to process the data that is collected. There are a lot of factors to be considered but the primary factor is the size of the website.
If a website has thousands of pages and is generating new pages every day, Google needs to limit the number of pages it will index and prioritize which pages it should index first. If other criteria are met, other pages will be indexed eventually.
Lack of Importance
Google’s algorithm is smart enough to understand if a specific page can be important to users or not. If Google decides not to index a specific page, then it just decided that at the moment, it is not important for users but it will again reevaluate the page the next time it crawls it.
Thin Content
Google may decide not to index a page if the content is too lacking or what we call thin content. A webpage that has thin content is considered to provide no value to users. As mentioned above, Google wants to use its resources efficiently so it will rather focus on indexing other pages that provide value to users.
How to Fix Crawled – Currently Not Indexed Status
Unlike statuses under Errors where you can verify manually that fixes have been made, there is no way to manually tell Google that you’ve made improvements on the pages under the Excluded section.
According to Google Search Console Help, there is no need for manual requests to reindex pages under this status because they will reevaluate the page again eventually.
However, if you want to make sure Google indexes these pages the next time they crawl it, here are a few steps you could take.
Improve Content
Improving the content of a webpage does not only mean adding more words to the count but also adding content that is useful for the users when they enter your website. You should think about how a certain page plays a role in the user’s journey on your website.
Obviously, this is the case for pages that you intend for users to see. But if these are unnecessary pages like archives and feed pages, it is totally fine to leave them as is. In fact, you may want to consider blocking them from being crawled to save up your crawl budget.
Increase Internal Links
Increasing the number of internal links going to the page solves two problems; first, Google will crawl the page more frequently, and second, Google will give more importance to it. If you have other content on your website such as blog posts, I highly recommend that you add a few internal links to pages Google crawled but has not indexed yet.
Reduce Click-Depth
Click-depth is the number of clicks a user needs to take to land on a specific page. If a user needs to click many times before they are able to reach the desired page, that is bad for the user experience and the page can be considered as not important by Google. A good number would be limiting important pages to 1 to 2 clicks. I wouldn’t go beyond 4 clicks as that is too deep already.
Difference between Crawled Not Indexed and Discovered
“Crawled – Currently Not Indexed” and “Discovered – Currently Not Indexed” are two different statuses that can be quite confusing to some. The main difference between the two is in “Crawled – Currently Not Indexed”, Google already discovered the page and crawled it already and decided not to index it yet.
For “Discovered – Currently Not Indexed”, Google was able to discover the page through crawling under pages but decided not to crawl it yet therefore not index it yet.
This means pages under “Discovered – Currently Not Indexed” have less importance to Google compared to pages under “Crawled – Currently Not Indexed”. If you want to improve the status of pages here,
Key Takeaway
The ‘Crawled – Currently Not Indexed’ status type in Google Search Console may not provide much info on hindsight but it is really helpful in identifying which parts of our websites Google seem to ignore. This provides us SEOs more opportunities for optimizations. It is also important to note that this status does not require immediate action unless your important pages are found here. Remember to make sure that the next time Google crawls the page, you’re giving Google a reason to index the page and rank it in the search results.